Less is More : Pourquoi j'ai remplacé Git par Jujutsu.
Introduction
En informatique, l’aphorisme “Less is More” revient souvent. Avec Jujutsu (jj), il prend une forme très concrète : un modèle mental plus simple peut réduire la friction quotidienne dans la gestion de versions.
Dans cet article1, je ne vais pas chercher à “prouver” que jj est supérieur à git. Je vais montrer, sur un cas concret, pourquoi certaines opérations courantes : interrompre un travail, réorganiser ses modifications, corriger un commit non atomique ou résoudre un conflit, deviennent plus naturelles avec jj.
Jujutsu
Jujutsu est un outil de gestion de versions écrit par Martin von Zweigbergk et qui a fait de la simplicité sa qualité essentielle. Il est né d’un constat simple : Git est complexe à utiliser, non pas à cause de sa syntaxe mais à cause de la complexité de son architecture et du modèle mental associé.
Jujutsu vise à simplifier ce modèle mental : Plusieurs opérations qui demandent des mécanismes différents dans git se ramènent au changeset courant. On réfléchit moins à l’outil, davantage au travail à faire.
C’est ce que je vais essayer de vous démontrer à travers des exemples concrets, issus de problèmes déjà rencontrés.
Dans un souci de brièveté, j’utiliserai ici indistinctement jj pour parler de l’exécutable et du projet Jujutsu.
Modèle mental
Pour être à l’aise avec git, il faut généralement jongler avec plusieurs concepts distincts :
- L’index (staging area) pour préparer un commit
- Les branches et HEAD pour savoir où l’on travaille
- Le stash pour mettre de côté un travail en cours
- Le rebase, reset ou reflog quand il faut réécrire ou récupérer une situation
Ce modèle est puissant, mais il répartit des opérations proches sur plusieurs mécanismes différents.
jj en comparaison se comprend facilement à travers un modèle mental simple :
- Les changesets avec le changeset courant (
@) - Les bookmarks, l’équivalent des branches, sont des pointeurs simples
- L’op_log pour
jj undo
Changeset, bookmark, op_log : avec ces trois concepts, vous avez déjà de quoi comprendre et utiliser l’essentiel de jj au quotidien. La suite montrera comment cette simplicité fluidifie les manipulations courantes.
Mise en place
Il existe différentes manières de travailler avec jj, mais parmi tous les workflow possibles, celui que je vais utiliser dans cet article est un workflow assez répandu et facile à mettre en oeuvre dans le cas où vous utilisez déjà git avec un dépôt distant sur Github.
L’idée est de travailler localement uniquement avec jj et de pousser des branches vers Github, pour gérer le merge de la manière habituelle via des PR sur github.
Une fois jj installé, la première étape est l’initialisation du dépôt pour pouvoir utiliser jj :
Dans le répertoire du projet, taper jj vous donnera la marche à suivre :
jj
Hint: Use `jj -h` for a list of available commands.
Error: There is no jj repo in "."
Hint: It looks like this is a git repo. You can create a jj repo backed by it by running this:
jj git init --colocated
jj nous indique qu’il a bien détecté le répertoire .git/ mais pas le .jj/ associé à un répertoire géré par jj et nous donne la commande pour initialiser ce répertoire jj git init --colocated2
Vous noterez, ici quelque chose qui n’est pas propre à jj, mais caractéristique des outils pensés pour leur utilisateur :
un message d’erreur qui ne se contente pas d’expliquer le problème, mais qui donne en plus la solution.
Une fois jj git init --colocated exécuté, le répertoire .jj/ apparaîtra et vous pourrez utiliser jj pour gérer ce répertoire.
Exécuter à nouveau jj produira alors un tout autre résultat :
@ kxupqzzp arhuman@gmail.com 2026-04-05 17:45:31 fe20df75
│ (empty) (no description set)
◆ mknymppu arhuman@gmail.com 2026-04-05 16:25:30 main main@origin git_head() 756e0c3e
│ Initial commit
~
Par défaut, jj sans argument lance jj log car c’est la commande la plus utilisée.
C’est une autre illustration du soin porté par jj pour vous faciliter la vie.
L’affichage vous présente déjà à peu près toutes les informations que vous aurez à maîtriser pour travailler avec jj :
On y voit 2 changesets, qui ont chacun un changeid et un hash.
Le premier changeset a pour changeid mknymppu, pour hash 756e0c3e et pour description “Initial commit”.
Son enfant a pour changeid kxupqzzp et pour hash fe20df75, comme nous n’avons encore rien fait dans le répertoire,
il est indiqué comme étant vide via le (empty) et sans description (no description set).
Ce changeset commence par le caractère @ pour indiquer que c’est le changeset courant.
Avec git, un même travail peut vous obliger à jongler entre plusieurs mécanismes distincts : branche courante, index, stash, historique. Avec jj, tout part du changeset courant.
Voyez cela comme un “commit de travail” permanent :
- Pas de
git add: Chaque fichier sauvegardé dans votre éditeur est immédiatement inclus dans le changeset courant. - Pas de
git stash: Si vous changez de branche, votre travail en cours reste attaché à son changeset. Vous ne perdrez plus jamais de code dans les méandres du stash. - Le changeid : C’est le nom stable du changeset. Le hash, lui, change dès que vous modifiez le code ou les parents.
Structure initiale
Je vous avais promis un cas concret, alors travaillons sur une mini API de gestion de tâches.
J’utiliserai une arborescence simplifiée :
taskapi/
├── go.mod
├── go.sum
├── main.go
├── task.go
├── store.go
└── store_test.go
Une fois ces fichiers créés, je fais mon premier commit
jj commit -m "ajout API minimale"
Working copy (@) now at: nloxqvts 3355af0e (empty) (no description set)
Parent commit (@-) : kxupqzzp c34d52da ajout API minimal
Pour vous faciliter la vie, jj a créé un nouveau changeset vide qui devient le changeset courant.
Notez au passage, que je n’ai pas eu à ajouter des fichiers dans un index ou spécifier une liste de fichiers.
Par défaut le changeset prend en compte tous les fichiers du répertoire.
Avec git, j’aurais dû sélectionner explicitement les fichiers (git add) avant de committer.
Mais attention, une bonne gestion du .gitignore est donc encore plus à l’ordre du jour pour éviter de versionner vos binaires ou votre .env
Après ce commit on voit bien un changeset enfant ajouté avec une description correspondant au message de commit.
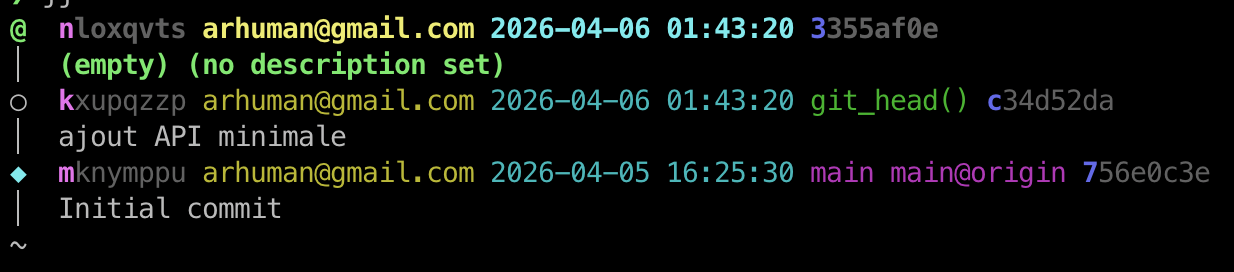
@ nloxqvts arhuman@gmail.com 2026-04-06 01:43:20 3355af0e
│ (empty) (no description set)
○ kxupqzzp arhuman@gmail.com 2026-04-06 01:43:20 git_head() c34d52da
│ ajout API minimale
◆ mknymppu arhuman@gmail.com 2026-04-05 16:25:30 main main@origin 756e0c3e
│ Initial commit
~
Au passage, notez que certaines parties du changeid (nloxqvts) et du hash (3355af0e) sont en gras, c’est le préfixe minimal qui garantit l’unicité de l’identifiant. Dis autrement vous allez pouvoir manipuler vos changesets avec des (parties d’) identifiants de quelques caractères seulement.
Premier développement
Si je veux ajouter un nouvel endpoint /tasks en post, je modifie le code.
// main.go
package main
import (
"encoding/json"
"net/http"
)
func main() {
http.HandleFunc("/tasks", tasksHandler)
http.ListenAndServe(":8080", nil)
}
func tasksHandler(w http.ResponseWriter, r *http.Request) {
+ if r.Method == http.MethodPost {
+ var body struct {
+ Title string `json:"title"`
+ }
+ json.NewDecoder(r.Body).Decode(&body)
+ task := AddTask(body.Title)
+ json.NewEncoder(w).Encode(task)
+ return
+ }
if r.Method == http.MethodGet {
json.NewEncoder(w).Encode(ListTasks())
return
}
// store.go
package main
var tasks = []Task{}
+var nextID = 1
+
+func AddTask(title string) Task {
+ task := Task{
+ ID: nextID,
+ Title: title,
+ Done: false,
+ }
+ nextID++
+ tasks = append(tasks, task)
+ return task
+}
func ListTasks() []Task {
return tasks
// store_test.go
package main
import "testing"
+func TestAddTask(t *testing.T) {
+ task := AddTask("test")
+ if task.Title != "test" {
+ t.Fatal("wrong title")
+ }
+}
+
func TestListTasksInitiallyEmpty(t *testing.T) {
got := ListTasks()
et je commit :
jj commit -m "ajout du endpoint /tasks en POST"
Là encore jj nous montre que le changeset à bien été ajouté comme enfant, et qu’un nouveau changeset vide a été créé.
C’est le changeset courant et nous sommes prêts à ajouter nos modifications.
Working copy (@) now at: lotzmxpu 4fa2ec2b (empty) (no description set)
Parent commit (@-) : nloxqvts f558246f ajout du endpoint /tasks en POST
Commit interrompu
Pour la modification suivante je décide de refactorer store.go
// store.go
package main
-var tasks = []Task{}
-var nextID = 1
+type TaskStore struct {
+ tasks []Task
+ nextID int
+}
+
+var store = TaskStore{
+ tasks: []Task{},
+ nextID: 1,
+}
func AddTask(title string) Task {
task := Task{
- ID: nextID,
+ ID: store.nextID,
Title: title,
Done: false,
}
- nextID++
- tasks = append(tasks, task)
+ store.nextID++
+ store.tasks = append(store.tasks, task)
return task
}
func ListTasks() []Task {
- return tasks
+ return store.tasks
}
Mais avant de finir, je me souviens que je n’ai pas défini de licence pour mon code.
Je crée donc un nouveau changeset pour y travailler.
Avec git, j’aurais probablement dû utiliser un stash ou créer une branche intermédiaire.
Mais avec Jujutsu un simple jj new fera l’affaire.
@ lzpqoloy arhuman@gmail.com 2026-04-06 05:43:51 057e22a1
│ (empty) (no description set)
○ lotzmxpu arhuman@gmail.com 2026-04-06 05:43:36 git_head() 467b3f7e
│ (no description set)
○ nloxqvts arhuman@gmail.com 2026-04-06 05:42:30 f558246f
│ ajout du endpoint /tasks en POST
○ kxupqzzp arhuman@gmail.com 2026-04-06 01:43:20 c34d52da
│ ajout API minimale
◆ mknymppu arhuman@gmail.com 2026-04-05 16:25:30 main main@origin 756e0c3e
│ Initial commit
~
Notez que le changeset courant est maintenant un changeset vide, et que le changeset parent n’a pas de description.
Travail hors contexte
Je crée mon fichier LICENSE.txt
# LICENSE.txt
MIT License...
et je commite ma modification : jj commit -m "ajout de LICENSE.txt"
Naviguer dans les changesets
Une fois la licence ajoutée je peux retourner à mon refactoring
jj edit lo
Un ls me permet de constater que j’ai bien retrouvé le code quitté auparavant, le fichier LICENSE.txt étant absent.
Là où git vous force à “empaqueter” votre travail (stash ou commit temporaire) avant de bouger, jj traite votre changeset comme un commit de plein droit : il vous attend sagement là où vous l’avez laissé.
Erreur détectée
Je décide d’ajouter un champ CreatedAt au model :
// task.go
package main
+import "time"
+
type Task struct {
ID int
Title string
Done bool
+ CreatedAt time.Time
}
Je finis mon refactoring de store.go et je profite pour supprimer un commentaire inutile.
// store.go
package main
+import "time"
...
task := Task{
ID: store.nextID,
Title: title,
Done: false,
+ CreatedAt: time.Now(),
}
C’est alors que je réalise en faisant un jj show (l’équivalent d’un git diff) que mes modifications relèvent de deux intentions différentes.
Correction naturelle
Le changeset étant par nature modifiable, je vais simplement le scinder en deux changesets “atomiques”
jj split je sélectionne store.go avec la touche espace, je continue avec la touche c et je donne une description pour le nouveau changeset créé “refactoring de store.go”
jj log
❯ jj
○ lzpqoloy arhuman@gmail.com 2026-04-06 05:49:56 0e104fbe
│ ajout de LICENSE.txt
@ swutzrxp arhuman@gmail.com 2026-04-06 05:49:56 c7a8a72b
│ (no description set)
○ lotzmxpu arhuman@gmail.com 2026-04-06 05:49:34 git_head() 6b3a4a69
│ refactoring de store.go
○ nloxqvts arhuman@gmail.com 2026-04-06 05:42:30 f558246f
│ ajout du endpoint /tasks en POST
○ kxupqzzp arhuman@gmail.com 2026-04-06 01:43:20 c34d52da
│ ajout API minimale
◆ mknymppu arhuman@gmail.com 2026-04-05 16:25:30 main main@origin 756e0c3e
│ Initial commit
~
On voit bien le nouveau changeset qui est apparu en parent avec pour description “refactoring de store.go”
Avec jj, corriger un commit non atomique se fait en une commande simple (jj split), alors qu’avec Git cela nécessite souvent un git reset --soft, un git add -p interactif et un git commit. C’est une gymnastique mentale plus lourde.
Re-modifier un changeset
Je suis toujours sur le changeset (swutzrxp) sur lequel je n’ai pas fini de travailler.
J’ajoute un test pour le CreatedAt
// store_test.go
package main
- import "testing"
+ import (
+ "testing"
+ "time"
+ )
func TestAddTask(t *testing.T) {
task := AddTask("test")
if task.Title != "test" {
t.Fatal("wrong title")
}
+ if task.CreatedAt.IsZero() {
+ t.Fatal("CreatedAt should be set")
+ }
+
+ if time.Since(task.CreatedAt) > time.Minute {
+ t.Fatal("CreatedAt seems incorrect")
+ }
}
Et j’en profite pour noter une idée dans store.go
CreatedAt: time.Now(),
+ // TODO: ajouter UpdatedAt
}
Ceci étant fait, je change la description avec un message explicite :
jj desc -m "ajout du champ CreatedAt"
La description comme le code, n’est pas figée. Cela favorise la production de code, la réorganisation n’étant pas contrainte par le contenu ou la description des commits. On peut avancer sur le code d’abord, puis réorganiser l’historique ensuite.
Avec git, obtenir cet état proprement m’aurait demandé d’anticiper davantage : soit découper mes changements avant le commit avec l’index interactif, soit réécrire ensuite l’historique avec une combinaison de reset, add partiel et amend/rebase.
Avec jj, je peux d’abord avancer, puis restructurer après coup sans changer de modèle mental : je manipule toujours des changesets.
Réorganisation logique des changesets
Une chose me dérange encore, j’aimerais bien regrouper les commits d’ajout du endpoint de task et d’ajout du CreatedAt
❯ jj log
○ lzpqoloy arhuman@gmail.com 2026-04-06 05:54:12 767a77a1
│ ajout de LICENSE.txt
@ swutzrxp arhuman@gmail.com 2026-04-06 05:54:12 b65c4507
│ ajout du champ CreatedAt
○ lotzmxpu arhuman@gmail.com 2026-04-06 05:49:34 git_head() 6b3a4a69
│ refactoring de store.go
○ nloxqvts arhuman@gmail.com 2026-04-06 05:42:30 f558246f
│ ajout du endpoint /tasks en POST
○ kxupqzzp arhuman@gmail.com 2026-04-06 01:43:20 c34d52da
│ ajout API minimale
◆ mknymppu arhuman@gmail.com 2026-04-05 16:25:30 main main@origin 756e0c3e
│ Initial commit
~
Encore une fois jj rend cela trivial :
jj rebase -r s -d n
Gestion des conflits
Mais comme souvent un conflit apparait :
Rebased 1 commits to destination
Rebased 1 descendant commits
Working copy (@) now at: swutzrxp 318b863e (conflict) ajout du champ CreatedAt
Parent commit (@-) : nloxqvts f558246f ajout du endpoint /tasks en POST
Added 0 files, modified 1 files, removed 0 files
Warning: There are unresolved conflicts at these paths:
store.go 2-sided conflict
New conflicts appeared in 1 commits:
swutzrxp 318b863e (conflict) ajout du champ CreatedAt
Hint: To resolve the conflicts, start by creating a commit on top of
the conflicted commit:
jj new swutzrxp
Then use `jj resolve`, or edit the conflict markers in the file directly.
Once the conflicts are resolved, you can inspect the result with `jj diff`.
Then run `jj squash` to move the resolution into the conflicted commit
La première chose à retenir est que jj possède une commande fantastique jj undo qui vous permet d’annuler vos commandes : vous pourriez facilement revenir à l’état d’avant sans conflit et résoudre ce conflit en amont. Mais à des fins pédagogiques je vais vous montrer à quel point c’est généralement facile de le faire avec jj.
Car là encore jj nous explique clairement le problème et nous donne la solution :
jj new swutzrxp
On se retrouve dans un changeset vide fils du conflit où on va pouvoir le corriger. Il suffit pour cela d’éditer le fichier, le résoudre en enlevant les marqueurs et la section erronée (side #1 ici).
package main
func AddTask(title string) Task {
task := Task{
ID: nextID,
Title: title,
Done: false,
<<<<<<< Conflict 1 of 1
%%%%%%% Changes from base to side #1
- CreatedAt: time.Now(),
+++++++ Contents of side #2
CreatedAt: time.Now(),
// TODO: add UpdatedAt
>>>>>>> Conflict 1 of 1 ends
}
nextID++
tasks = append(tasks, task)
return task
}
func ListTasks() []Task {
return tasks
}
jj nous indique que le conflit a disparu dans le changeset courant
@ trzmmrns arhuman@gmail.com 2026-04-06 05:58:30 e1bd96f4
│ (no description set)
× swutzrxp arhuman@gmail.com 2026-04-06 05:55:20 git_head() 318b863e conflict
│ ajout du champ CreatedAt
│ ○ lzpqoloy arhuman@gmail.com 2026-04-06 05:55:20 6f214b06
│ │ ajout de LICENSE.txt
│ ○ lotzmxpu arhuman@gmail.com 2026-04-06 05:49:34 6b3a4a69
├─╯ refactoring de store.go
○ nloxqvts arhuman@gmail.com 2026-04-06 05:42:30 f558246f
│ ajout du endpoint /tasks en POST
○ kxupqzzp arhuman@gmail.com 2026-04-06 01:43:20 c34d52da
│ ajout API minimale
◆ mknymppu arhuman@gmail.com 2026-04-05 16:25:30 main main@origin 756e0c3e
│ Initial commit
~
On peut alors descendre la correction dans le parent avec un jj squash.
Pour constater que le conflit a disparu sur swutzrxp
@ wryptxru arhuman@gmail.com 2026-04-06 05:59:43 e02d4f06
│ (empty) (no description set)
○ swutzrxp arhuman@gmail.com 2026-04-06 05:59:43 git_head() 52a9f82a
│ ajout du champ CreatedAt
│ ○ lzpqoloy arhuman@gmail.com 2026-04-06 05:55:20 6f214b06
│ │ ajout de LICENSE.txt
│ ○ lotzmxpu arhuman@gmail.com 2026-04-06 05:49:34 6b3a4a69
├─╯ refactoring de store.go
○ nloxqvts arhuman@gmail.com 2026-04-06 05:42:30 f558246f
│ ajout du endpoint /tasks en POST
○ kxupqzzp arhuman@gmail.com 2026-04-06 01:43:20 c34d52da
│ ajout API minimale
◆ mknymppu arhuman@gmail.com 2026-04-05 16:25:30 main main@origin 756e0c3e
│ Initial commit
~
Non seulement la résolution est simple, mais un conflit n’étant pas un état comme dans git mais une modification comme une autre, je pourrais aussi choisir de travailler sur d’autres changesets et repousser cette résolution à plus tard.
Publication vers Github
Enfin quand je suis satisfait de la qualité et l’organisation de mes commits, je peux créer une branche (un bookmark dans la terminologie jj) avec :
jj bookmark create -r swutzrxp feat/add-task
Puis la pousser vers Github :
jj git push --bookmark feat/add-task --allow-new
Le reste relève de la gestion de Pull Request classique sur Github, pour qui du reste cette branche est indissociable d’une branche poussée par git
Synchronisation avec Github
Une fois la Pull Request mergée je peux re-synchroniser mes branches distantes :
jj git fetch
Puis simplifier pour mon affichage de log en réalignant la branche main locale avec la branche main distante
git switch main
git pull
J’ai choisi de faire ces opérations à la main pour vous montrer, comme la synchronisation manuelle est simple, mais jj vous offre la possibilité de le faire automatiquement via la commande jj bookmark track main --remote origin
Commandes utiles
J’ai essayé dans mes exemples de montrer comment les commandes les plus problématiques avec git étaient simples avec jj
Mais les opérations simples avec git le restent avec jj :
jj st(équivalent àgit status)jj file show -r @ task.go(presque équivalent degit show HEAD:task.go)jj file annotate store.go(équivalent degit blame store.go)jj log -r 'diff_lines("CreatedAt")'(équivalent degit log -G 'CreatedAt')jj log -r 'diff_lines("empty title", "main.go")'(équivalent degit log -G 'empty title' -- main.go)
Conclusion — changement de paradigme
J’espère vous avoir donné envie d’essayer jj : un outil qui ne punit pas les erreurs et rend les corrections faciles.
Mais au-delà de l’aspect technique, c’est un changement dans la manière de penser son travail.
Avec git, j’ai souvent ce petit pincement au moment de lancer une commande “dangereuse” : rebase, reset --hard, stash drop. La peur de perdre du travail ou de créer un chaos irréversible est réelle. Je finis par éviter certaines opérations, ou par les faire avec une prudence excessive qui casse le rythme.
Avec jj, cette peur disparaît presque entièrement, car tout est réversible :
jj undo annule n’importe quelle commande, pas seulement la dernière.
Un conflit n’est pas un état bloquant, mais un changeset comme un autre, que l’on peut résoudre plus tard ou même laisser en plan pour autre chose.
Je peux réorganiser mon historique, scinder un commit, en changer la description, tout cela après coup, sans craindre de tout casser. Le code devient malléable, l’historique aussi.
Bien sûr, jj n’est pas parfait. Il est plus jeune que git, son écosystème est plus petit et les bonnes pratiques restent à définir. Mais sur le plan du confort quotidien, il change vraiment la donne.
Car si Git est pratique quand vous ne faites pas d’erreur, Jujutsu l’est surtout quand vous vous trompez.
Article qui est une réécriture d’une présentation un peu trop sommaire à mon goût donnée à mes collègues de l’EPFL. ↩︎
Certaines versions indiquent toujours
jj git initmaisjj git init --colocatedest souvent le meilleur choix : il permet de transformer votre dossier Git actuel en dépôt Jujutsu sans changer vos habitudes de navigation ou vos outils d’édition. ↩︎
